Tech · Oct 10, 2025
Boosting Wan2.2 I2V inference on 8xH100s, 2.5x faster than baseline with Sequence Parallelism
Authored by Muhammad Ali Afridi.

Authored by Muhammad Ali Afridi.
Introduction
We have seen the rapid development of open-source Video Generation DiT models with MOE architectures, such as Wan2.1[1] and Wan2.2[2].
It is very exciting to see that these open-source generation models are going to beat closed-source benchmarks. However, the inference speed of these models is still a bottleneck for real-time applications and deployment.
In this article, we will explore how we can speed up inference timings of Wan2.2 for the I2V task using the following clever techniques:
- Flash-Attention 3
- TensorFloat32 tensor cores for Matrix Multiplication
- Quantization: int8_weight_only
- Magcache
- torch.compile
We have developed a complete suite to test all these combinations, which can be applied one by one or simultaneously together to achieve the fastest inference speed for Wan2.2 I2V tasks.
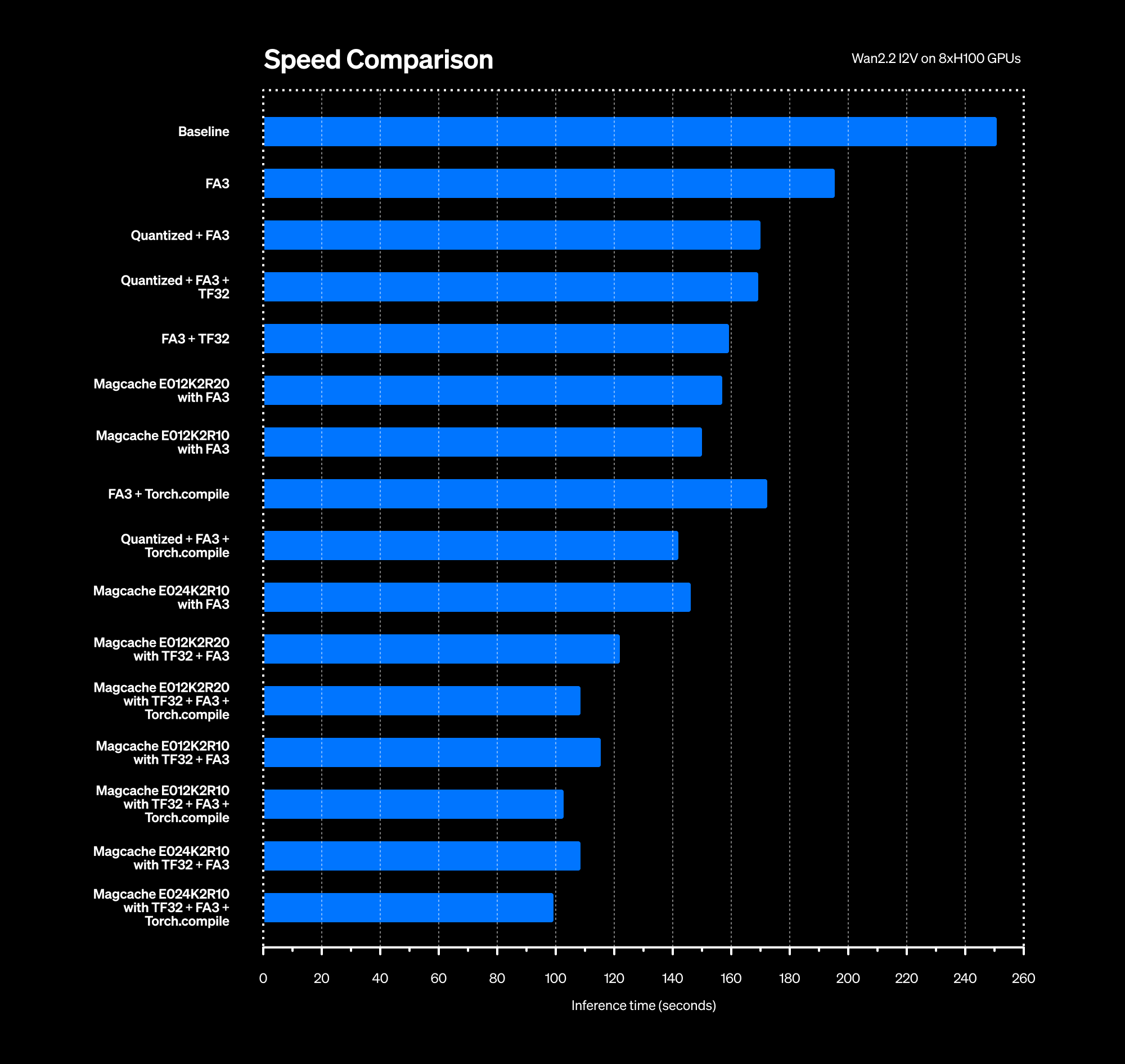
Note: We set up our experiments on 8 x NVIDIA H100 GPUs. Comparison has been done by generating 1280*720 resolution videos with 40 steps and 81 frames.
Baseline: Wan2.2 I2V on 8x H100 with Flash Attention 2
Since we are using H100 GPUs with 80 GB of memory each, the low-noise and high-noise models do not fit entirely on each GPU. For this purpose, we build our solutions on Wan2.2's[2] original GitHub repository instead of Diffusers to use FSDP (Fully Sharded Data Parallel)[4] to make models fit into our memory. We also explore quantization to bypass FSDP. In this article, we will focus on optimizing the inference speed of Wan2.2 I2V, totally based on the original repository.
To get started, simply clone the repo and install the requirements:
git clone https://github.com/morphicfilms/wan2.2_optimizations.git
cd wan2.2_optimizations
pip install -r requirements.txtMake sure to have the models downloaded:
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.2-I2V-A14B --local-dir ./Wan2.2-I2V-A14BTo generate a video, simply use:
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."This is our baseline. Flash attention 2 is enabled by default, and it takes 250.70s to generate 1 video with 1280x720 resolution in 40 inference steps with 81 frames.
This is the base video with which we will compare our optimized generated videos to determine the quality vs. speed trade-offs. The base seed is set to 50 by default.
Optimization Recipes
Flash-Attention 3
Hopper architectures perform pretty well with Flash Attention 3. To set up FA3 clone the following repo outside the directory of our repo and install via:
git clone <https://github.com/Dao-AILab/flash-attention.git>
cd flash-attention
pip install wheel
cd hopper
python setup.py install
export PYTHONPATH=$PWDAfter setting up FA3, which might take some time, you can rerun the inference as it is:
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."The inference time this time drops to 195.13s, which is a 1.28x boost alone. The video quality is the same.
TensorFloat32 tensor core optimization
Pytorch allows us to set TF32 on matmul and on cuDNN to True[3]. They are False by default. This gives better performance on matmul and convolutions on torch.float32 tensors by rounding input data to have 10 bits of mantissa. To use this optimization, simply pass in an additional argument --tf32 True:
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside. --tf32 True"Which actually does the following:
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = TrueThis brings down our inference time to 159.55 seconds, which is a 1.57x boost from the baseline. The following is the video quality comparison with the baseline video:
Quantization
Quantization is yet another way to make inference fast and also allow both the high-noise and low-noise models to fit in each H100 GPU, thus bypassing FSDP entirely. We use '''int8_weight_only''' for our quantization config.
Note: Since the precision of models' weights has been reduced to int8, applying TensorFloat32 optimization shows no speed benefit with quantization, as shown in the graph above. That's because now internal matmuls are being done on int8 instead of TF32, and there's nothing left for the tensor cores to optimize.
If you are not familiar with torchao quantization, you can refer to this documentation[5]. Here, we simply install the latest torchao, which is capable of quantizing the Wan2.2 low noise & high noise models:
pip install -U torchaoTo use the quantization, simply pass in --quantize True:
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside." --quantize TrueThis does give us speed benefit when used with FA3, but not as that of TF32+FA3. It brings down inference time to 170.24 seconds, which is a 1.47x boost from the baseline. Following is the 1:1 Comparison with the baseline:
Note that passing dit_fsdp will have no effect since we bypass FSDP to quantize both models.
Magcache
This less lossy cache method exploits an important concept of the magnitude ratio of successive residual outputs[6]. The ratio decreases monotonically, steadily in most timesteps, while rapidly in the last several steps. It has been shown that it performs better than TeaCache in both speed and video quality.
The original implementation[7] only supports inference on 1x H100. The same is the case with TeaCache[8]. We develop on the same concept to scale it to 8x H100s to push the limits and leverage the sequence parallelism along with it. We found that a setting of E012K2R20 (error threshold =012, K =2, and retention ratio = 0.2) works pretty good in maintaining video quality and providing speed benefit.
To use magcache, try the following:
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --ulysses_size 8 --t5_fsdp --dit_fsdp --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside." --save_file "output.mp4" --use_magcache --magcache_K 2 --magcache_thresh 0.12 --retention_ratio 0.2This reduces inference time to 157.10 seconds, which is nearly the same as that of TF32+FA3. A 1:1 Comparison of this optimization with baseline (which shows minimal to no change) on base_seed 50 is as follows:
But TF32 can be additionally applied by passing the additional argument:
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --ulysses_size 8 --t5_fsdp --dit_fsdp --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside." --save_file "output.mp4" --use_magcache --magcache_K 2 --magcache_thresh 0.12 --retention_ratio 0.2 --tf32 TrueNow, we can generate 1 video with 1280x720 resolution of 81 frames in 40 inference steps in 121.56 seconds, which is a 1.97x boost. We can see how tf32 optimization is causing about a 30s boost here! A 1:1 Comparison of this optimization with the baseline on base_seed 50 is as follows:
More inference boosts are shown in the graph above with other magcache settings such as E012K2R10 and E024K2R10. The higher the error threshold and K value (skip steps), the more it hurts the video quality. E012K2R20 is a good pick to preserve the quality.
Torch.compile
Last but not least, we let low-noise and high-noise models compile to push the boundaries. We can set torch.compile with mode="max-autotune-no-cudagraphs", which can help us to achieve the best performance by generating and selecting the best kernel for the model inference. If you are not familiar with torch.compile, you can look up the official documentation[9].
To compile both models, pass an extra argument --compile True:
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --ulysses_size 8 --t5_fsdp --dit_fsdp --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside." --save_file "output.mp4" --compile TrueWe need to warm up the model first to measure the speedup correctly. The actual compilation happens during the first inference pass.
We can also pass custom modes using the --compile_mode argument. Note that max-autotune will take a lot of time during the warmup because it looks for the most optimized kernel possible by enabling CUDA graphs by default on the GPU. More information can be found here[10].
Note that due to non-compile-friendly distributed operations and dynamic slicing in the rope_apply function in the code, we have to let fullgraph=False to allow both models to compile without errors.
Benchmarks with Torch Compile
FA3+torch.compile
Inference Time: 172.87 seconds
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --ulysses_size 8 --t5_fsdp --dit_fsdp --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside." --save_file "output.mp4" --compile TrueFA3+Quantization+torch.compile
Inference Time: 142.40 seconds
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --ulysses_size 8 --t5_fsdp --dit_fsdp --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside." --save_file "output.mp4" --quantize True --compile TrueFA3+TF32+torch.compile
Inference Time: 142.73 seconds
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --ulysses_size 8 --t5_fsdp --dit_fsdp --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside." --save_file "output.mp4" --tf32 True --compile TrueUltimate super fast recipe: FA3+ TF32 + Magcache E012K2R20 + Torch Compile
Without compromising video quality, you can try the following max-autotune-no-cudagraphs compile mode:
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --ulysses_size 8 --t5_fsdp --dit_fsdp --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside." --save_file "output.mp4" --tf32 True --use_magcache --magcache_K 2 --magcache_thresh 0.12 --retention_ratio 0.2 --compile TrueInference Time: 109.81s, 2.28x boost from baseline.
A 1:1 Comparison of this final, highly optimized, and quality-preserved video on base_seed 50 is as follows:
You can always tweak the Magcache parameters to speed it up even further, but that will start to show artifacts in the video. For example, E024K2R10 gives inference time of 98.87 seconds, which is a 2.53x boost!
Conclusion
In this article, we showcase powerful optimization techniques to speed up the latency of Wan2.2, which is a quality open source model. This setting allows production environments to cost-efficiently run models like these faster without visual loss of video quality. The overall comparison of video quality can be seen in this grid:
Special thanks to Modal for powering our multi-GPU inference setup that helped us test and build, and scale Wan2.2 performance improvements.
References
[1] Wan2.1: https://github.com/Wan-Video/Wan2.1
[2] Wan2.2: https://github.com/Wan-Video/Wan2.2
[3] PyTorch CUDA Documentation: https://docs.pytorch.org/docs/stable/notes/cuda.html
[4] Fully Sharded Data Parallel: https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/
[5] TorchAO Quantization: https://github.com/pytorch/ao/blob/main/torchao/quantization/README.md
[6] Magcache: https://arxiv.org/pdf/2506.09045
[7] Magcache Original Implementation: https://github.com/Zehong-Ma/MagCache/blob/main/MagCache4Wan2.2/README.md
[8] TeaCache Original Implementation: https://github.com/ali-vilab/TeaCache/blob/main/TeaCache4Wan2.1/README.md
[9] Introduction to Torch Compile: https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html
[10] Torch Compile Usage: https://docs.pytorch.org/docs/stable/generated/torch.compile.html